sql注入总结
SQL注入基础
SQL注入就是指wb应用程序对用户输入数据的合法性没有判断,前端传入后端的参数是攻击者可控的,并且参数带入数据库查询,攻击者可以通过构造不同的SQL语句来实现对数据库的任意操作。
一般情况下,开发人员可以使用动态SQL语向创建通用、灵活的应用。动态SQL语句是在执行过程中构造的,它根据不同的条件产生不同的SQL语句。当然,SQL注入按照不同的分类万法可以分为很多种,如报错注入、盲注、Union注入等。
MySQL注入知识点
MySQL版本
MySQL >= 5.0
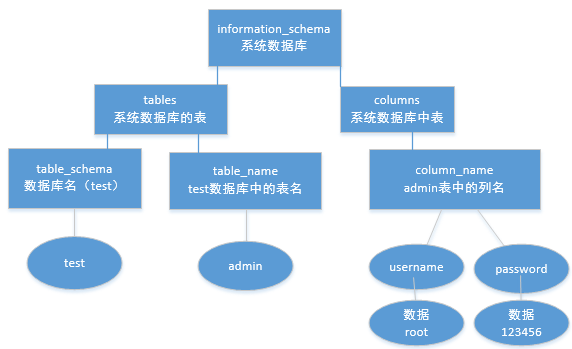
在MySQL 5.0版本之后,MySQL默认在数据库中存放一个“information_schema“的数据库,在该库中,我们需要记住三个表名,分别是SCHEMATA、TABLES和
COLUMNS。
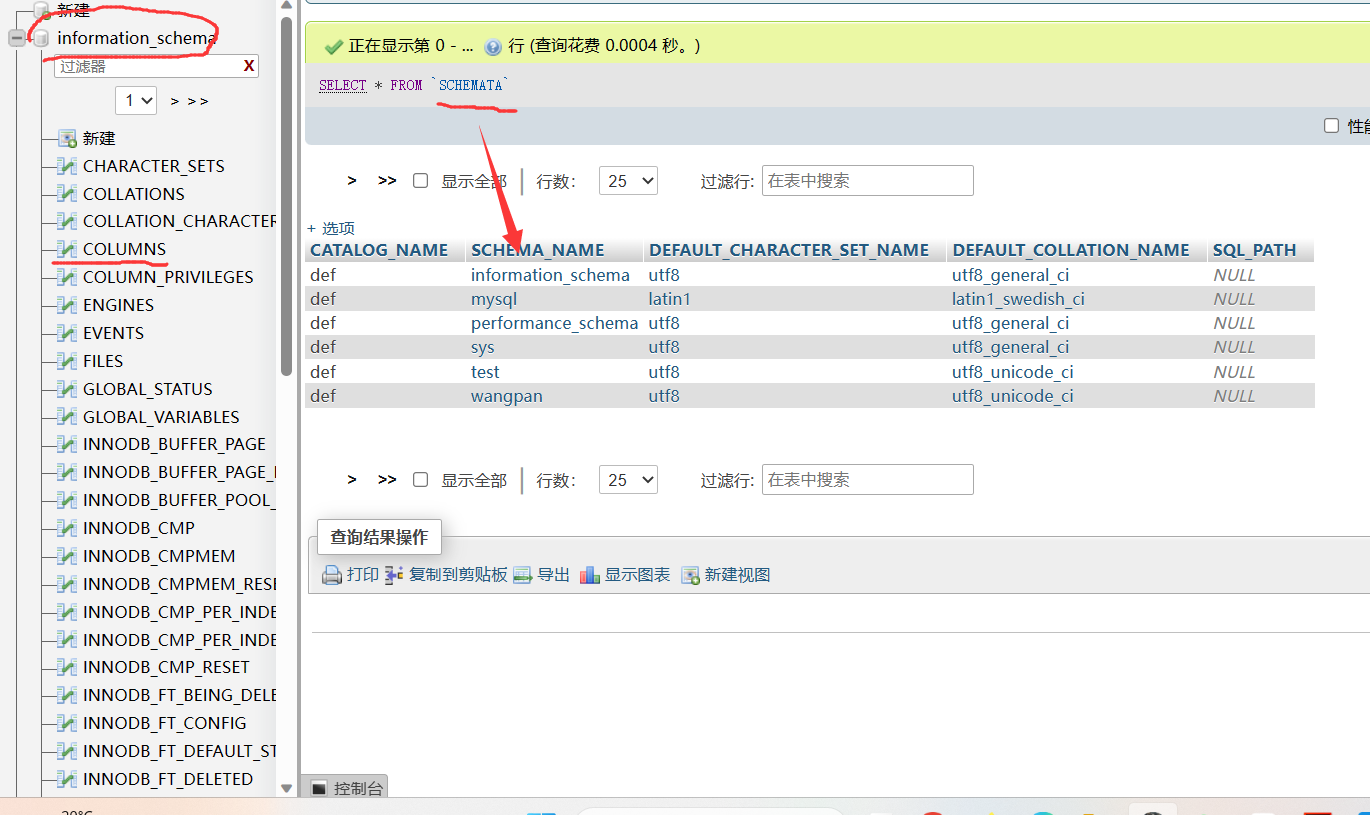
SCHEMATA表存储该用户创建的所有数据库的库名。我们需要记住该表中记录数据库库名的字段名为SCHEMA_ NAME。
1 | |
TABLES表存储该用户创建的所有数据库的库名和表名。我们需要记住该表中记录数据库库名和表名的字段名分别为TABLE_ SCHEMA和TABLE_NAME。
1 | |
COLUMNS表存储该用户创建的所有数据库的库名、表名和字段名。我们需要记住该表中记录数据库库名、表名和字段名的字段名为TABLE_SCHEMA 、TABLE_NAME和COLUMN_NAME。
1 | |
结构图(TABLES表和COLUMNS表):
了解了这些知识,有助于理解后面的一些SQL注入语句。
MySQL < 5.0
才疏学浅,还没遇到过低于5.0版本的情况,但可以知道MySQL < 5.0 没有信息数据库”information_schema“,所以只能手工枚举爆破(二分法思想),该方式通常用于盲注。
MySQL查询语句
在不知道任何条件时:
1 | |
知道已知条件时:
1 | |
1 | |
1 | |
万能密码
注意其中的一些符号’一般正确的应该是英文的',而不是中文字符
万能密码
1 | |
asp aspx万能密码
1 | |
PHP万能密码
1 | |
jsp 万能密码
1 | |
limit的用法
limit一般用来限制输出记录数量
limit的使用格式为limit m,n,其中m是指记录开始的位置,从0开始,表示第一条记录;n是指n条记录。
例如:
1 | |
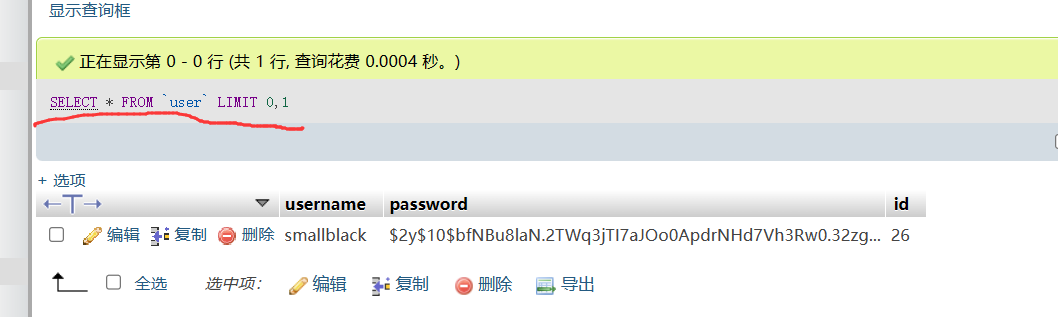
limit 0,1表示从第一条记录开始,取一条记录。
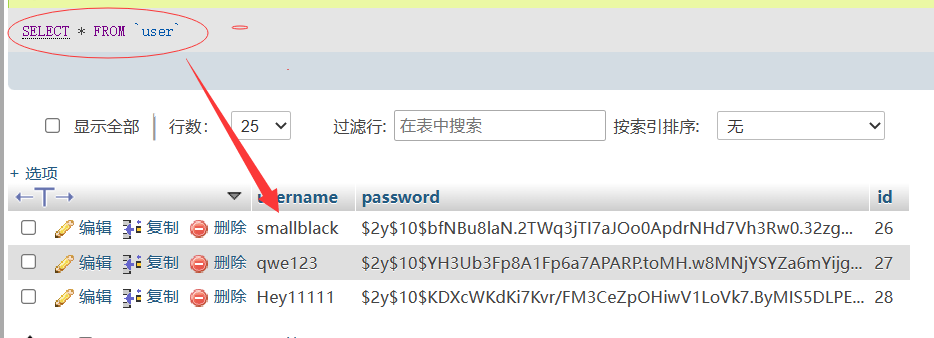
如果不使用limit,就会直接取指定的全部记录
1 | |
一些有用的函数
- database(): 当前网站使用的数据库
1 | |
- version(): 当前MySQL的版本
1 | |
user(): 当前MySQL的用户
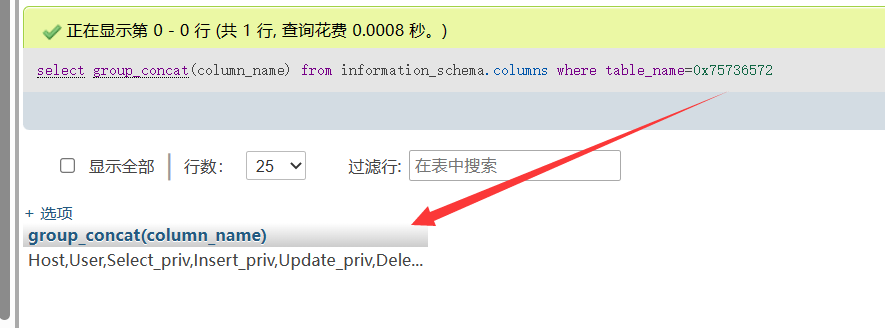
group_concat():可以将多行数据转化为一行,便于观察
1 | |
- substr():截取xxx值,主要用于盲注
1 | |
与limit的区别:substr直接从1开始排序,而不像limit从0开始
- ord():进行ASCII转换
1 | |
s的ASCII码是115
- addslashes(): 对参数进行转义,可以转义单引号,导致查询语句无法闭合
1 | |
当传入a=test' ,就会被转义为test\
8.with rollup
with rollup 可以对 group by 分组结果再次进行分组,并在最后添加一行数据用于展示结果( 对group by未指定的字段进行求和汇总, 而group by指定的分组字段则用null占位)
具体的运用场景在后面会提及,还有一些,等以后遇到了再慢慢补充
fuzz
1 | |
注释符
常见的注释符一般为:#或–空格(–+)或/**/或%23
还有闭合号注释'1'='
GET和POST中注释符的使用:

内联注释
内联注释的形式:
1 | |
内联注释可以用于整个SQL语句中来执行。例如:
1 | |
当:
1 | |
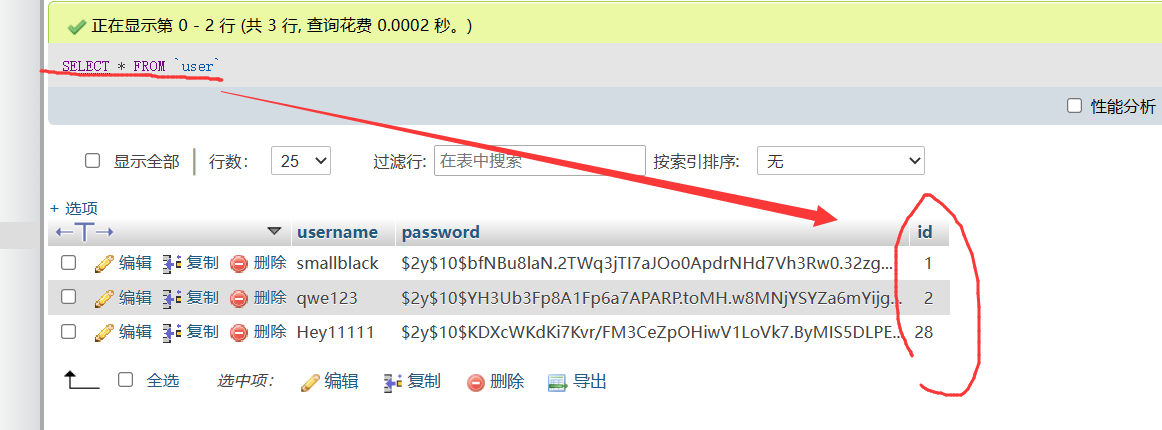
这个正常的查询语句可以返回 “user” 表中的所有数据
再当:
1 | |
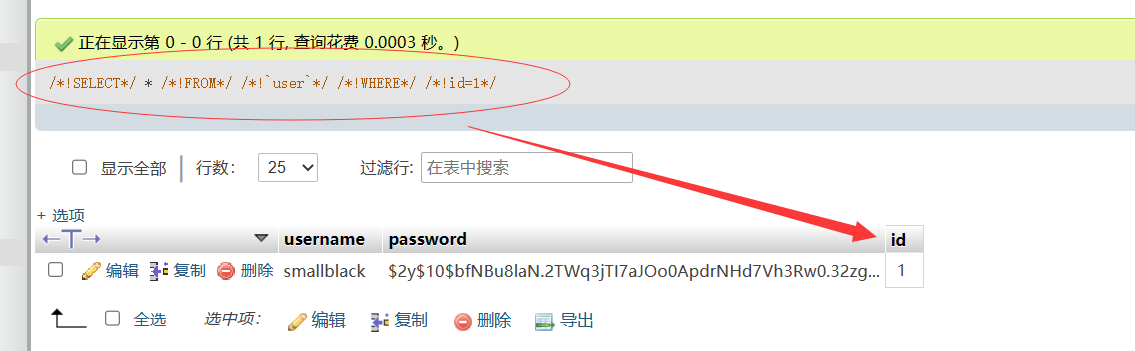
当然内联注释也可以用来绕waf,这个还是一个比较深入的知识点,先留着以后再学习补充。关于这个知识点,可以看学长的总结
闭合方式(闭合符)的判断
参考了CSDN的文章
判断了闭合符有助于我们后续对sql语句的构造
常见闭合方式:
1 | |
具体语句为:
1 | |
判断方式:
方法一
需要靶场会对 sql语句错误信息进行回显,也是最简单的判断方式
首先尝试:
1 | |
1、如果都报错,则为整形闭合。
2、如果单引号报错,双引号不报错。
然后尝试
1 | |
无报错则单引号闭合。报错则单引号加括号。
3、如果单引号不报错,双引号报错。
然后尝试
1 | |
无报错则双引号闭合。报错则可能为双引号加括号。
注意:这里的括号不一定只有一个,闭合符里是允许多个括号组合成闭合符的,具体要判段有多少个括号,可以使用二分法来快速判断。
二分法:如果确定了有括号,不确定有几层,测试括号的层数可以这样子:
先使用多层(比如6层'))))))),如果报错,那就减半为3层'))),和order by判断列数类似,直到加一个报错,少一个正确,可以得到答案。例如:
1 | |
还有就是有括号的时候,不带括号,或者括号少于真实数量的时候,sql语句是可以执行的,但是后面如果要拼接order by、union select这样子就不行了。
方法二
这个方法比较方便。使用空字符直接对sql语句进行截断,需要要求靶场允许传入空字符
1 | |
谁回显正常,就是谁,只有输入完全正确的时候才能正常显示,可以比较准确的判段括号个数
SQL注入类型
如果之前没了解过sql注入的话,可以先看union注入再回来按顺序看,union注入会先详细介绍手工注入的一些步骤
一些类型以CTFHUB上的题目为例
按变量类型分
数字型
先判断是什么类型(整数形或字符型)的注入
1 | |

如果是数字型注入的话,这里就会有一个逻辑判断,会判断出1不等于2,没有语法错误但有逻辑错误,所以返回一个null值,返回错误页面。
若1 and 1=2报错,就是整数型(数字型)注入
1 | |
若没报错,即字符型报错
1 | |
判断字段数,发现字段数为2
1 | |
判断回显位
1 | |
关于为什么是-1:如果不改的话执行后就不显示显示后面的内容,仍然查询的第一个的内容,也就是仍然查询?id=1,那么把?id=1的写成0或-1就可以了,写成它查询不到的内容,它比较发现是-1或者0那么它返回的值就是null,就会执行后面的内容。
爆出数据库
1 | |
指定数据库名sqli,爆表
1 | |
指定表flag,爆字段名
1 | |
指定字段flag,爆字段内容
1 | |

字符型
查询语句类似于:
1 | |
注入的时候需要用注释符注释掉‘(即包裹在外面的字符)
接下来的流程就跟数字型差不多,只是有点细微的区别
1 | |

按HTTP提交方式分
GET注入
也就是GET请求方法传参,例如:
1 | |
POST注入
可以用bp抓包或者hackbar等工具来注入比较方便
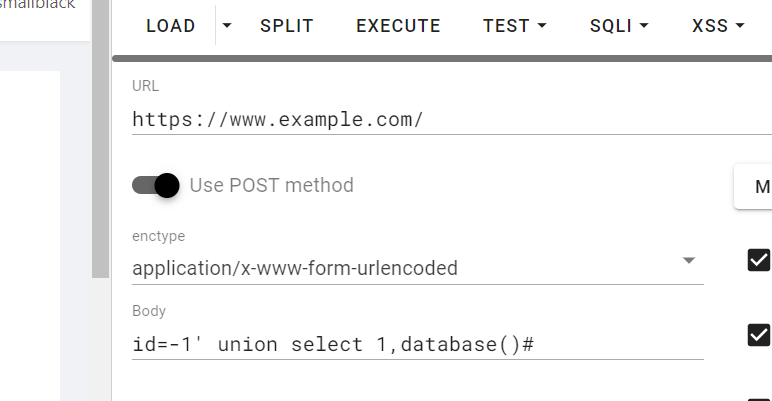
常用注入方式
union注入(基于它的手工注入步骤)
这里还是基于MySQL >= 5.0的注入流程
以GET型,查询语句为
1 | |
为例
1. 获取字段数
前面的这里的–+为注释符,对第n个字段进行排序,如果n的值大于真实的字段数量自然就会报错,从而确定字段数,例如:
1 | |
则字段数为一
这里也可以用group来判断字段数(对数据进行分组)
1 | |
2.判断回显位
由于有时候并不会回显全部字段,甚至只有一个回显位,因此需要判断回显位,从而使sql语句执行后能输出我们想要的结果,然后使用以下代码来判断回显位(以字段数为3为例)
1 | |
关于为什么是-1:如果不改的话执行后就不显示显示后面的内容,仍然查询的第一个的内容,也就是仍然查询?id=1,那么把?id=1的写成0或-1就可以了,写成它查询不到的内容,它比较发现是-1或者0那么它返回的值就是null,就会执行后面的内容。或:
1 | |
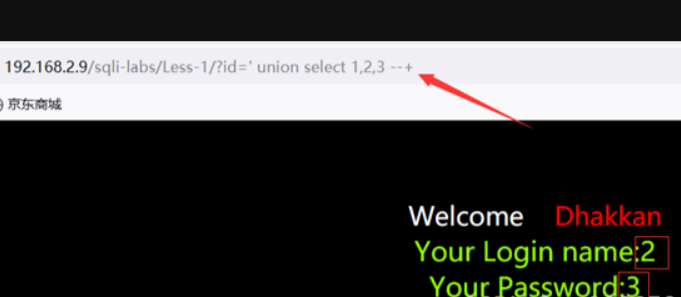
可以看到回显位位2,3
接下来就可以把2,3位换成想要查询的语句
1 | |
这样就是爆库(当前数据库)和爆用户名
3.获取系统数据库名
1 | |
1 | |
4.获取当前数据库名
1 | |
1 | |
5.获取数据库中的表
获取当前数据库中的所有表名
1 | |
获取指定数据库(hey)的所有表名
1 | |
6. 获取表里的列名(即字段名)
获得指定表(flag)下的所有字段名
1 | |
7.获取各个字段值
获取指定表(flag)中的指定字段(username和password)的值
1 | |
报错注入
利用条件:程序会将错误信息输出到页面上
所以可以利用一些函数来发生报错获取数据
这里利用updatexml()获取当前数据库名
1 | |
所以利用slesct语句继续获取数据库中的表名、字段名等
其中0x7e是ASCII编码,解码后为~
因为报错注入只显示一条结果,所以需要使用limit语句
当然除了updatexml(),还有一些函数可以用来报错注入
1 floor()和rand()
1 | |
2 extractvalue()
1 | |
3 updatexml()
1 | |
4 geometrycollection()
1 | |
5 multipoint()
1 | |
6 polygon()
1 | |
7 multipolygon()
1 | |
8 linestring()
1 | |
9 multilinestring()
1 | |
10 exp()
1 | |
布尔(Boolean)盲注
利用条件:页面对于SQL语句的返回结果不予以显示,并且对于真条件(true)和假条件(false)的返回内容存在差异
我们可以使用永真条件(or 1=1)和永假条件(and 1=2)来判断页面返回的内容是否存在差异,从而确定是否可以使用布尔盲注
以CTFHUB上的题目为例:
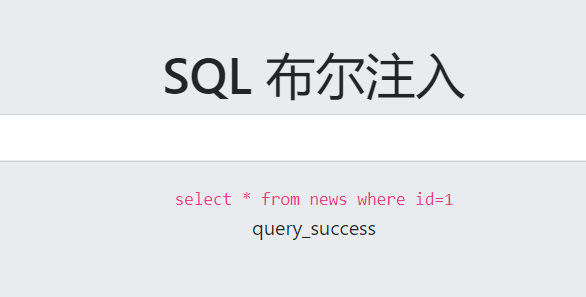
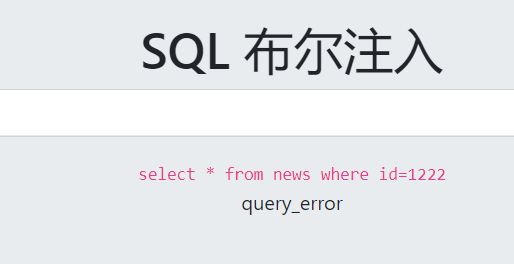
可以看到,当查询数据存在或正确的时候会返回query_success,否则就返回query_error
因此可以使用if(expr1,expr2,expr3),如果expr1的值为true,则执行expr2语句,如果expr1的值为false,则执行expr3语句。
那么就可以在expr1处插入判断语句,expr2处放上正确语法的sql语句,expr3处放上错误语法的sql语句,这样的话就可以判断我们的 exper1处的判断语句是否正确
1 | |
substr是截取的意思(是直接从1开始排序,而不像limit从0开始),这里是截取database()的值,从第一个字符开始(第一个1),每次只返回一个(第二个1),s意思是判断数据库第一个字母是否为s
也可以通过ord()函数来使用ASCII码的字符来查询
1 | |
s的ASCII码为115
盲注脚本为:
1 | |
时间盲注
时间盲注又称延迟注入,适用于页面不会返回错误信息,且只会回显一种界面,其主要特征是
利用sleep()函数或benchmark()等函数,让MySQL的执行时间变长,由回显时间来判断构造的条件是否正确。时间盲注与布尔盲注类似,布尔盲注基于两种回显页面,而时间盲注基于请求所用的时间。
1 | |
这里的意思是,如果当前数据数据库库名的长度大于1,就休眠5秒,否则就查询1.
脚本:
1 | |
当然如果sleep()函数不能用了,还可以使用benchmark()函数等其他一些方式,这里就先留个坑把,以后再补,可以先看学长的总结
堆叠注入
堆叠查询可以执行多条语句,多语句之间以分号隔开。分号;为MYSQL语句的结束符,若在支持多语句执行的情况下,可利用此方法执行其他恶意语句。比如有函数mysqli_multi_query(),它支持执行一个或多个针对数据库的查询,查询语句使用分号隔开。
1 | |
1 | |
可以看出,第二条SQL语句就是时间盲注的语句,后面的操作就和时间注入差不多。。。
但通常多语句执行时,若前条语句已返回数据,则之后的语句返回的数据通常无法返回前端页面,可考虑使用RENAME关键字,将想要的数据列名/表名更改成返回数据的SQL语句所定义的表/列名 。
改目标名
抄一下学长的解释。这道题select被过滤了,意味着这道题无法联合(union)注入,而它的内部查询语句为:
1 | |
网页的回显都是words这个表给的回显,而我们的flag放在数字表里,那么我们需要让数字表回显出来flag了,这时直接堆叠注入只会有words表的回显,这里的解决办法便是把数字表改为words表名。
1 | |
如果修改flag为id直接堆叠:
1 | |
然后用万能密码(例如:’ or 1=’1)即可显示出表里的所有数据,自然也包括flag了。
当然除了该目标名还有预处理、等一些方法,以后再慢慢补充
HTTP请求头注入
就是注入的位置不同(在请求头),比如User-Agent、cookie、X-Forwarded-For、Rerferer等等,也可以通过sqlmap –Level 5测试出来,或者自己测的时候注意一下就可以了
UA注入
UA就是User-Agent的缩写,中文名为用户代理,是Http协议中的一部分,属于头域的组成部分,它是一个特殊字符串头,是一种向访问网站提供你所使用的浏览器类型及版本、操作系统及版本、浏览器内核、等信息的标识。当然这里也可能存在sql注入
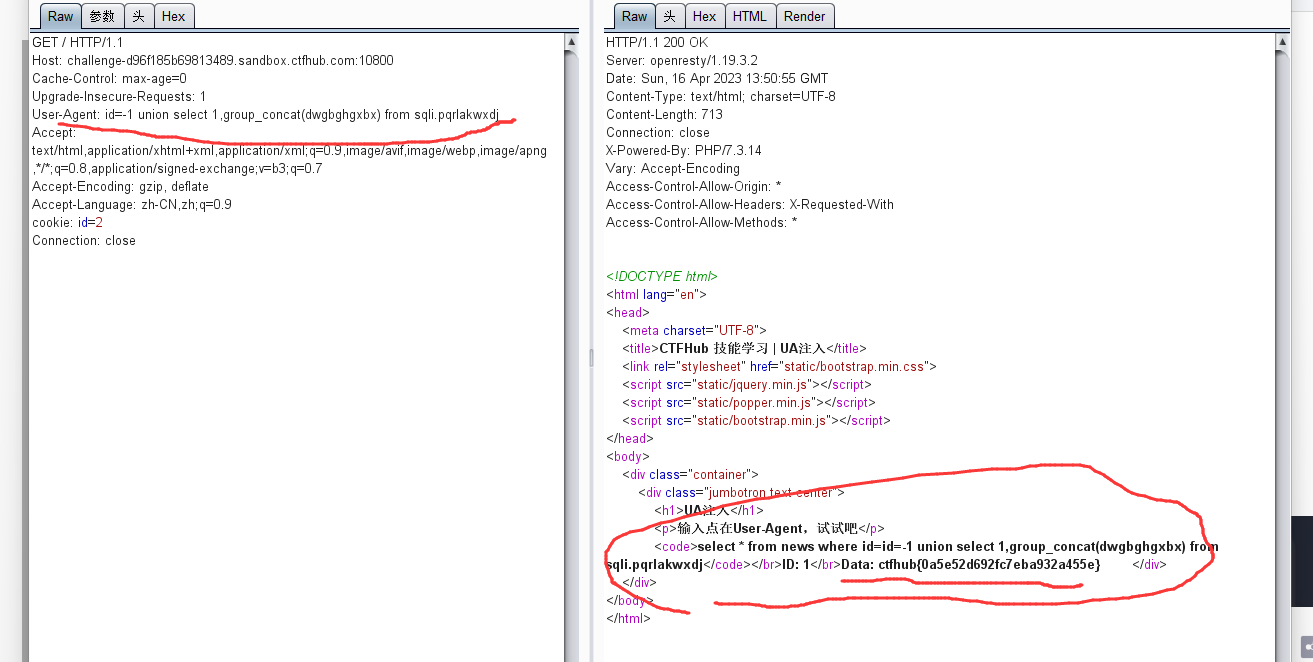
或者
1 | |
cookie注入
也就是注入点在cookie位置,可以用ModHeader比较方便操作,当然在bp也是可以的
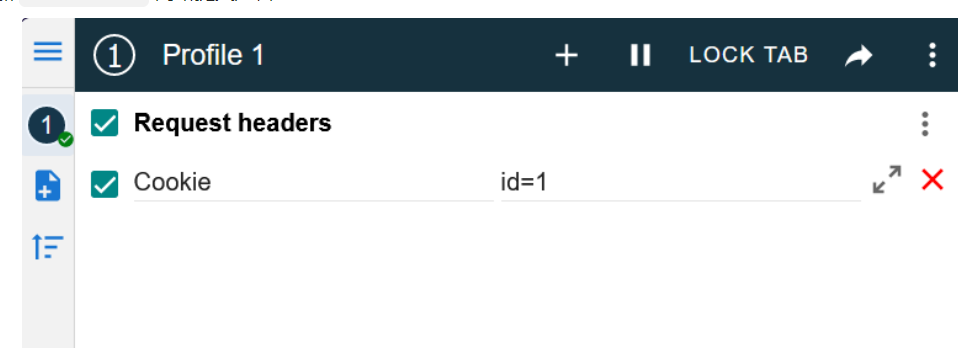
填好值后,刷新页面就可以执行了
接下来就是常规流程,跟之前差不多的操作,爆库、爆表、爆字段,最后拿到flag
Refer注入
步骤跟上面的注入差不多,只是这次注入点在Refer
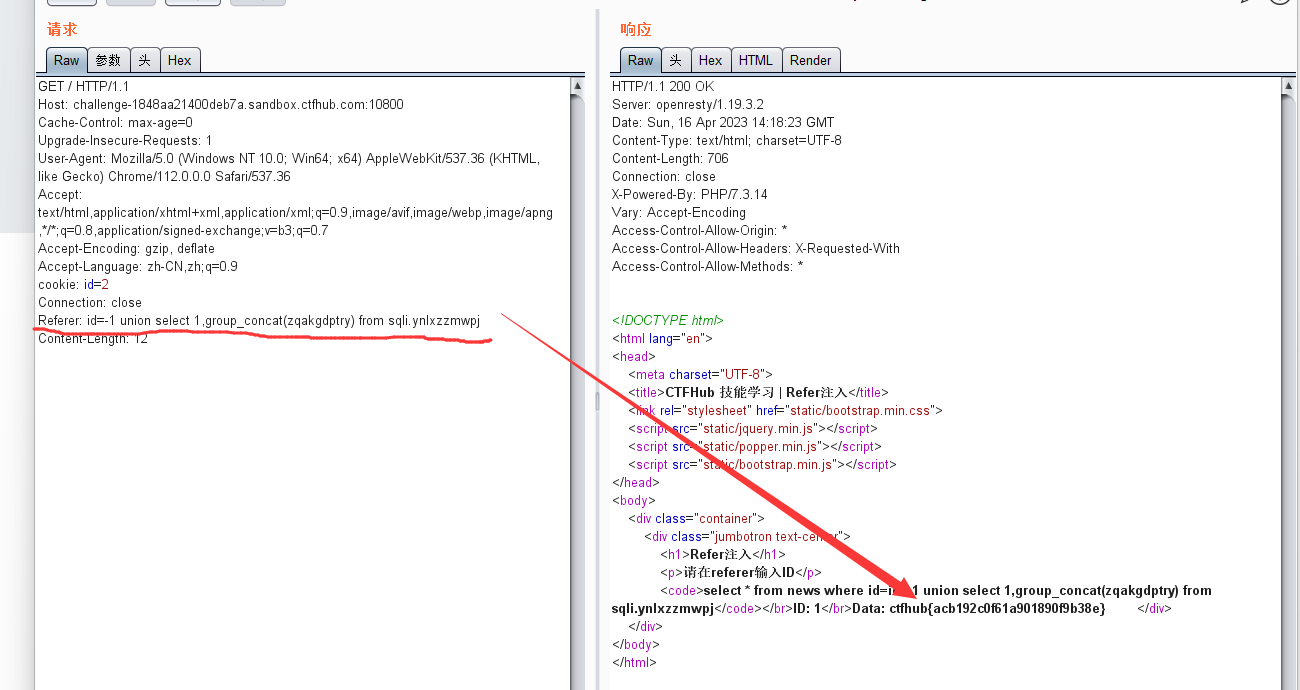
或者
1 | |
XFF注入
注入点在X-Forwarded-For
1 | |
1 | |
其他类型
二次注入
二次注入可以理解为,攻击者构造的恶意数据存储在数据库后,恶意数据被读取并进入到 SQL 查询语句所导致的注入。防御者可能在用户输入恶意数据时,对其中的特殊字符进行了转义处理;但在恶意数据插入到数据库时,被处理的数据又被还原并存储在数据库中,当 Web 程序调用存储在数据库中的恶意数据并执行 SQL 查询时,就发生了 SQL 二次注入。
比如,当我们浏览一些注册登录页面的时候,可以现在注册见页面注册username=test’,接下来访问xxx.php?username=test’,页面返回id=22;接下来再次发起请求xxx.php?id=22,这时候就有可能发生sql注入,比如页面会返回MySQL的错误。
访问xxx.php?id=test’ union select 1,user(),3%23,获得新的id=40,再访问xxx.php?id=40得到user()的结果,利用这种注入方式会得到数据库中的值。
当然通过这种方法可以修改一些已存在用户的密码,比如sqli-labs less 24(详细过程) ,假如我们注册了一个账号,账号名为admin’#,密码为111111
然后再去修改密码的页面将密码修改为1234567,则后端执行的sql语句就是:
1 | |
等价于:
1 | |
就相当于把admin的密码修改为1234567了。
也就是说其实在第一次注入尝试的时候,它的限制比较严格,并没有报错,然后第二次 由于限制不严存在sql注入漏洞
一个相关例子就是红岩杯的暴躁老哥的作业系统
宽字节注入
利用条件:
1.查询参数是被单引号包围的,传入的单引号又被转义符()转义,如在后台数据库中对接受的参数使用addslashes()或其过滤函数
2.数据库的编码方式为GBK
1 | |
在上述条件下,单引号’被转义,多出反斜杠(即%5c),所以就构成了%df%5c,而在GBK编码方式下,%df%5c是一个繁体字“連”,所以单引号成功逃逸。
嵌套查询
查询已知数据库的表名(sql)时,正常的查询语句如下
1 | |
但是由于单引号被转义,会多出反斜杠,导致SQL语句出错,所以要用到嵌套查询
1 | |
也就是把table_schema=’sql’换成了table_schema=(select+database())
这里括号内的查询语句会被先执行
base64注入
没什么好说的,就是传入的参数会经过一次base64加密,因此我们注入的时候要先base64加密一下
例如
1 | |
Dnslog注入
Dns在域名解析时会留下域名和解析ip的记录,利用这点我们可以使用Dnslog(日志)记录显示我们的注入结果。通过load_file()不仅可以查看本地文件,也可以访问远程共享文件。 ceye.io 及其子域名的查询都会到 服务器 A 上,这时就能够实时地监控域名查询请求了。DNS在解析的时候会留下日志,咱们这个就是读取多级域名的解析日志,来获取信息。简单来说就是把信息放在高级域名中,传递到自己这,然后读取日志,获取信息
利用条件:
1.SQL服务器能连接网络;
2.开启了LOAD_FILE() 读取文件的函数
3.dnslog回显只能用于windows系统
4.一般得是root权限
关于secure_file_priv
1、当secure_file_priv为空,就可以读取磁盘的目录。
2、当secure_file_priv为G:\,就可以读取G盘的文件。
3、当secure_file_priv为null,load_file就不能加载文件。
手工注入
可以利用在线的dns在线服务器记录下DNS请求
例如
1 | |
1 | |
‘\\‘代表Microsoft Windows通用命名约定(UNC)的文件和目录路径格式利用任何以下扩展存储程序引发DNS地址解析。双斜杠表示网络资源路径多加两个\就是转义了反斜杠。所以这样也可以
1 | |
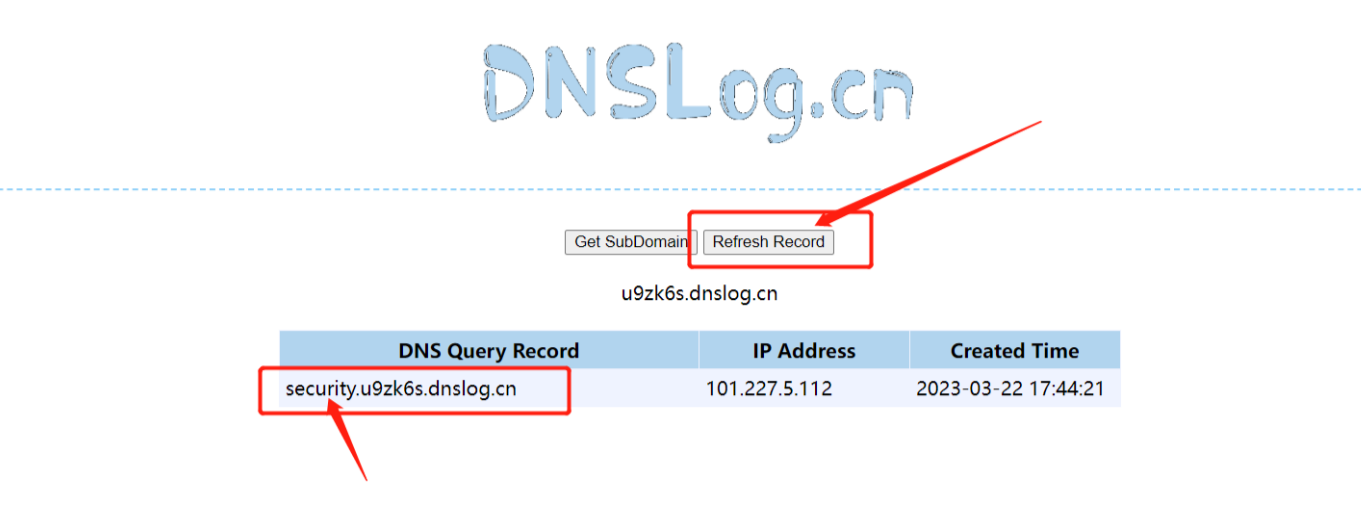
图中的security即刚才查询到的数据库名
工具注入
http://www.ceye.io ,先在该网站注册获得api和DNSurl
然后再配置好DnslogSqlinj工具(不知道为什么那个网站一直访问不了,先拿一下别人的图吧,有空再亲自试)
修改DnslogSqlinj的配置文件,填好API和DNSurl
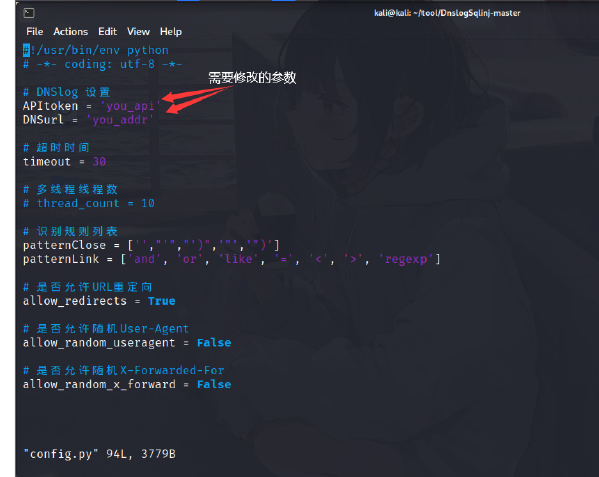
1 | |
之后的操作就跟sqlmap差不多了
({})内是dnslogSql自行添加的注入语句,还有闭合方式也要自己判断
Bypass技巧
关键字绕过
大小写绕过
如果仅只过滤了特定关键字的小写字符,正则对大小写不敏感,那么通过大小写就能成功绕过
比如select改成SelEct等
1 | |
双写绕过
如果这次过滤了关键字的大小写,也就是大小写绕过不再生效,但它仅仅把关键字的字符串替换为空(比如replace () 函数置换),并没有中断查询,那么就能通过双写来绕过
例如:select改成selselectect
1 | |
注释符绕过
方法有挺多的
用unio<>n代替union
查了一下<> 等价于 !=,所以是如何达到这个效果的目前还未搞懂,等以后看能不能遇到吧
用se/**/lect代替select。或者/*select*/代替select
如果是Mysql的数据库的话,也可以用前面提到的内联注释,用/*!select*/替代select
编码绕过
也可以说大多数情况下用于关键词绕过
url全编码
URL编码即(%+十六进制)
1 | |
十六进制
也可用于绕过引号
str -> hex
1 | |
flag转为16进制(hex)就是0x666c6167
ascii编码绕过
Test 等价于
1 | |
Unicode 编码
常用的几个符号的一些 Unicode 编码:
1 | |
二次URL编码
当尝试采用URL全编码的方式绕过的时候,如果是以GET方式传入的(如:?id=),由于服务器会自动对URL进行一次URL解码,所以要把关键词全编码两次
1 | |
绕过空格
编码绕过
也可以用编码绕过空格,具体就是前面提的那些
1 | |
内联注释
一般用/**/代替空格
例如
1 | |
括号绕过
也就是括号()代替空格,比如
1 | |
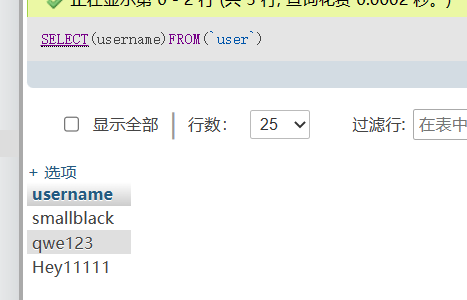
这样查询指定的字段是可以的,但是如果同时查询全部字段似乎是行不通的
1 | |

绕过引号
正常的查询语句一般为
1 | |
但如果过滤了引号,就无法执行SQL查询语句了
十六进制
因此,我们可以通过前面提到的转十六进制,来达到不使用引号便能查询的效果
1 | |
宽字节
使用条件比较苛刻,在 web 应用使用的字符集为 GBK 时,并且过滤了引号,就可以试试宽字节。%27 表示 单引号
1 | |
%df%5c是一个繁体字“連”,前面宽字节注入中讲过
绕过逗号
from to
就是from pos for len, 表示从 pos 个开始读取 len 长度的子串
盲注的时候为了截取字符串,我们往往会使用substr(),mid()。这些子句方法都需要使用到逗号,对于substr()和mid()这两个方法可以使用from to的方式来解决:
1 | |
等价于mid/substr(database(),1,1)
使用join
1 | |
等价于
1 | |
使用like
适用于 substr () 等提取子串的函数中的逗号,同样较多用于盲注的场景
1 | |
等价于
1 | |
t的ascii码为114
使用offset
适用于 limit 中的逗号被过滤的情况
1 | |
盲注的时候除了substr()和mid()需要使用逗号,limit也会使用逗号,比如
1 | |
过滤 or and xor (异或) not 绕过
1 | |
意思就是前面的字符等效于(=)后面的字符
绕过大小于号
盲注中,一般使用大小于号来判断 ascii 码值的大小(即二分法)来达到爆破的效果。当然有时候大小于号也会被限制
greatest()、least()
greatest (n1, n2, n3…): 返回 n 中的最大值
least (n1,n2,n3…): 返回 n 中的最小值,与上同理。
1 | |
可以达到相同的效果:
1 | |
如果database的第一个字符不是这里最大的则会返回64,则64=64,and后面成立。反之若大于64,就会返回大于64的数,也就不能实现64=64,导致不会有回显了。
least ()原理差不多
between
between a and b: 范围在 a-b 之间,包括 a、b。
1 | |
判断ascii值是否在64和128之间
绕过等于号
like
不加通配符的like执行的效果和 = 一致,所以可以用来绕过。
1 | |
同时,like有两个模式:_和%
_:表示单个字符,用来查询定长的数据
%:表示0个或多个任意字符
抄一下大佬的解释
1 | |
所以
1 | |
等效于
1 | |
in 关键字
1 | |
等效于
1 | |
判断第一个字符是否为t
rlike和regexp
这两者用法没什么差别
rlike:模糊匹配,只要字段的值中存在要查找的部分就会被选择出来,没有通配符效果和 = 一样
regexp:效果同上,就是需要数据库为MySQL
1、模糊查询字段中包含某关键字的信息。
如:查询所有包含“希望”的信息:select * from student where name rlike ‘希望’
**2、模糊查询某字段中不包含某关键字信息。
**如:查询所有不包含“希望”的信息:select * from student where name not rlike ‘希望’
3、模糊查询字段中以某关键字开头的信息。
如:查询所有以“大”开头的信息:select * from student where name rlike ‘^大’
4、模糊查询字段中以某关键字结尾的信息。
如:查询所有以“大”结尾的信息:select * from student where name rlike ‘大$’
5、模糊匹配或关系,又称分支条件。
如:查询出字段中包含“幸福,幸运,幸好或幸亏”的信息:
select * from student where name rlike ‘幸福|幸运|幸好|幸亏’
所以
1 | |
等效于
1 | |
strcmp()
3)strcmp (str1,str2): 若所有的字符串均相同,则返回 0,若根据当前分类次序,第一个参数小于第二个,则返回 -1,其它情况返回 1
1 | |
通过返回值(1或-1)来判断第一个字符是否为t
绕过where
可以用having来替代
1 | |
where 后面要跟的是数据表里的字段,如果我把ag换成avg(goods_price)也是错误的!因为表里没有该字段。而having只是根据前面查询出来的是什么就可以后面接什么。
详细见:正确理解MySQL中的where和having的区别
其他
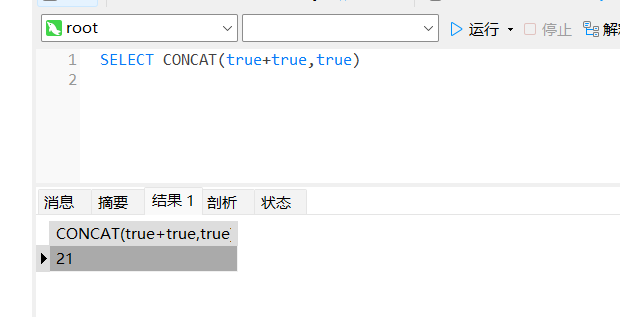
true
true可以用来表示数字1,结合char可以构造出字符

space()
space(number)可以输出指定数量的空格,但我在ctfshw的题目上试时,不论多少个,它输出值都是空,所以我加了个replace来将空格显式的表达出来
假设题目场景是个输出字符检测
1 | |
1 | |
这样可以通过数有多少个a,来将其数字通过ascii转化成字符,可得到对应位数的字符
理论上只要找到没被preg_match的字符,就能绕过它的输出检测
然而这个方法还是比较鸡肋的,如果题目仅仅检测输出,那完全有很多更方便的方法,盲注、写文件等
replace会把不支持的字符全变为?,比如用“邪恶”的全角字符𝐚
1 | |
总结与感悟
2023.4.24
陆陆续续写了一周多,期间借鉴了许多大佬的文章,收获了挺多。也留了一些坑,等以后回来补,例如绕waf等知识,第一次在学长的文章看到的,但没有实际接触过,所以想着过段时间再回来慢慢补上一些知识点。总的来说,还是一个美妙的体验,第一次写这么长的文章嘿嘿嘿。
参考: